
index cover Problems That Cause Pages to Be Excluded
Book a Free Consultation Now
Would you like to know more about this topic?
Contact us on WhatsApp and get a free consultation from our experts
Contact on WhatsApp NowAn index cover is a technique where an index contains all the data needed to answer a query without accessing the main table or page, which significantly improves performance and efficiency. In SEO and database optimization, index cover concepts help reduce processing time, improve system speed, and ensure better data retrieval for both users and search engines. At Nofal Seo, we apply advanced indexing and technical SEO strategies to help businesses optimize performance, improve crawl efficiency, and achieve stronger search visibility.
What is a index cover?
A cover index is a database indexing technique where the index contains all the fields required to satisfy a query without needing to access the original table or document. When an index cover is properly designed, the database engine can retrieve query results directly from the index, which significantly reduces disk I/O operations and improves query performance, especially for read-heavy workloads and complex filtering conditions.
This type of index is commonly used in systems that handle large datasets and frequent queries. By including all queried columns inside the index itself, the database avoids additional lookups, making searches faster and more efficient. Cover indexes are particularly valuable in analytics, reporting, and high-traffic applications where speed and scalability are critical.
Cover indexes are closely related to high-search concepts such as database indexing, query optimization, index-only scans, performance tuning, and read optimization. At Nofal Seo, we apply these technical principles when working with large-scale data-driven websites to ensure optimal performance and crawl efficiency.
To understand why cover indexes are important, consider the following points:
-
They reduce the need to access the main table or document
-
Queries run faster because data is fetched directly from the index
-
They improve performance for frequently executed read queries
-
They help databases handle large volumes of traffic efficiently
-
Proper index design minimizes resource consumption
What is index coverage in SEO?
Index coverage in SEO refers to how well search engines like Google crawl, index, and process the pages of a website. The concept of index cover in this context focuses on ensuring that important pages are accessible, indexable, and visible in search results without technical barriers such as errors, exclusions, or incorrect directives.
A healthy index coverage status means that search engines can properly understand which pages should appear in search results and which should not. SEO professionals analyze index coverage reports to identify errors, excluded pages, warnings, and crawling issues that may negatively affect organic visibility and traffic.
This topic is strongly connected to keywords such as Google Search Console, index coverage report, crawl errors, page indexing issues, and technical SEO audits. At Nofal Seo, we use index coverage analysis to detect hidden SEO problems, recover lost visibility, and ensure that high-value pages are indexed correctly.
Why index coverage matters for SEO performance:
-
It helps identify pages blocked from indexing unintentionally
-
It prevents loss of organic traffic due to technical errors
-
It ensures important pages are visible in search results
-
It improves crawl efficiency and site structure
-
It supports long-term SEO growth and stability
Covering index Postgres
In PostgreSQL, a covering index is an index that includes all the columns required by a query, allowing PostgreSQL to perform an index-only scan. The idea behind an index cover in Postgres is to optimize query execution by eliminating the need to read data from the main table, which can significantly improve performance in large databases.
PostgreSQL supports covering indexes through the use of included columns, enabling developers to fine-tune indexing strategies for specific query patterns. This approach is especially useful in applications with complex filtering and frequent read operations, where performance and scalability are essential.
This concept is associated with search terms like PostgreSQL indexing, index-only scans, query planner, database performance optimization, and large-scale data systems. At Nofal Seo, we collaborate with technical teams to align database performance improvements with SEO and site speed optimization strategies.
Key benefits of covering indexes in PostgreSQL:
-
Faster query execution through index-only scans
-
Reduced disk access and lower server load
-
Better performance for high-traffic applications
-
Improved scalability for growing datasets
-
More efficient handling of complex queries
Check Index Coverage Report
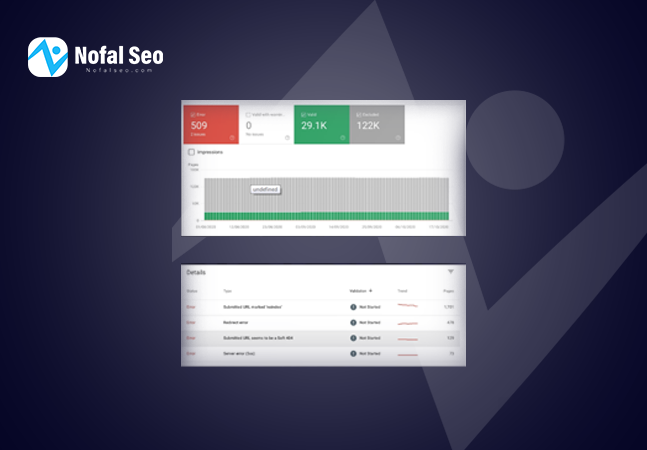
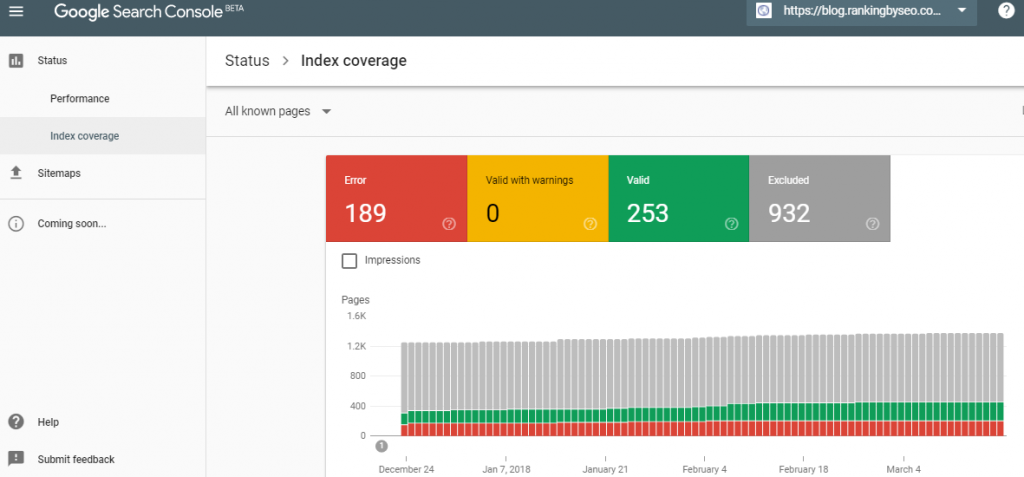
The Search Console Coverage report tells you which pages have been crawled and indexed by Google, and how index cover issues affect why URLs are in a specific state. You can use it to detect any errors that occur during the crawling and indexing process.
To check the index coverage report, go to “Google Search Console” and click “Coverage” (just below the index). Once you open it, you’ll see a summary of four different states that categorize your URLs:
- Error: These pages cannot be indexed and will not appear in search results due to some errors.
- Valid with caveats: These pages may or may not be shown in Google search results.
- Valid: These pages have been indexed and can be shown in search results. You don’t need to do anything.
- Excluded: These pages have not been indexed and will not appear in search results. Google believes that you do not want to index them or consider the content unworthy of indexing.
You need to check and correct all the pages in the error section as soon as possible because you may lose the opportunity to direct traffic to your site. If you have time, review the pages included in the valid status with a warning as there may be some vital pages that should under no circumstances appear in search results. Finally, make sure that the excluded pages are the pages that you do not want to be indexed. There are several variants of the index coverage issue that we will present below.
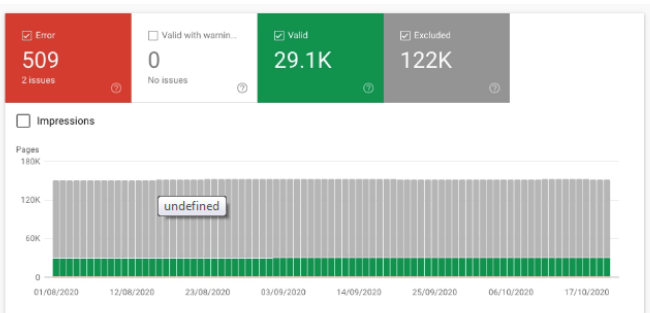
How to solve the problems in each case of index coverage
error condition
Server 5XX Errors: These are the URLs that return the 5xx status code to Google and are an index coverage issue.
Actions to be taken:
- Check the type of status code 500 that is returned. Here you have a complete list of each server error status code definition.
- Reload the URL to see if the error persists. 5xx errors are temporary and require no action.
- Verify that your server is not overloaded or misconfigured. In this case, ask your developers for help, or contact your hosting provider.
- Perform log file analysis to check your server’s error logs. This practice provides you with additional information about the problem.
- Review the changes you’ve made to your website recently to see if any of them are the root cause. eg) plugins, new backend code, etc.
Redirect errors
- Redirect string was too long
- redirection loop
- Redirect URL exceeded the maximum URL length
- There was a wrong or empty URL in the redirect string
Get rid of redirect strings and loops. Make each URL do only one redirect. In other words, a redirect from the first URL to the last URL.
- Check if search engines want to index the page in question or not.
- If you don’t want it indexed, upload an XML sitemap to remove the URL.
- Conversely, if you want to index it, change the instructions in the Robots.txt file. Here is a guide on how to edit a robots.txt file.
- The URL that was sent is marked with ‘noindex’
- These pages were submitted to Google via an XML sitemap, but have a “noindex” directive in either the bots meta tag or HTTP headers.
Actions to be taken:
- If you want the URL to be indexed, you have to remove the noindex.
- If there are URLs that you don’t want Google to index, remove them from your XML sitemap
-
URL sent to Google by XML sitemap error 401. This status code tells you that you are not authorized to access the URL. You may need a username and password, or there may be access restrictions based on IP address, one of the index coverage issues.
Actions to be taken:
- Check if the URLs should return the 401 error. In this case, remove it from the XML sitemap.
- If you don’t want them to display a 401 code, remove the HTTP authentication if any.
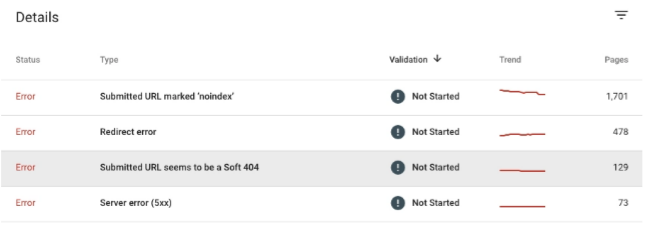
Submitted URL not found (404)
Actions to be taken:
- Check if you want to index the page or not. If yes, then fix it, so that it returns a status code of 200. You can also set a 301 redirect to a URL, so that it returns a proper page. Remember that if you choose redirect, you need to add the custom URL to the XML sitemap and remove the address that gives a 404.
- If you don’t want the page to be indexed, remove it from the XML sitemap.
The URL that was submitted has a crawling problem
I submitted the URL for indexing purposes to GSC but Google cannot crawl it due to a different issue than the one above.
Actions to be taken:
- Use the URL Check tool to get more information about the cause of the problem.
- Sometimes these errors are temporary, so they do not require any action.
Valid with warning status
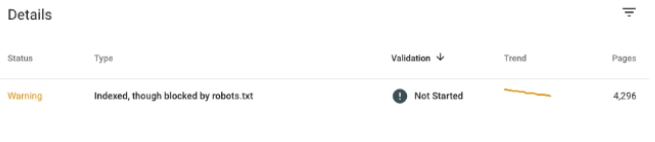
Actions to be taken:
- Google does not recommend using robots.txt to avoid page indexing. Alternatively, if you don’t want to see these pages indexed, use noindex in the meta robots or HTTP response header.
- Another good practice to prevent Google from accessing the page is to implement HTTP Authentication.
- If you do not want to block the page, make the necessary corrections in the robots.txt file.
- You can specify the rule that is blocking the page using the robots.txt test tool.
excluded case
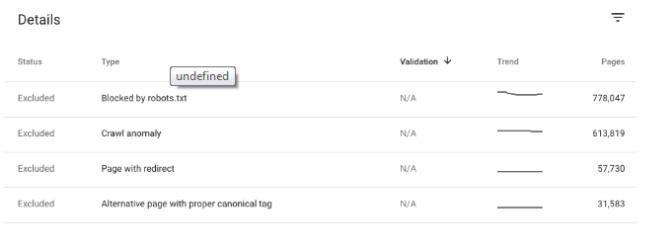
1- excluded with “noindex”
You are telling search engines not to index the page by giving the “noindex” command.
Actions to be taken:
- Check if you don’t really want the page to be indexed. If you want the page to be indexed, remove the “noindex” tag.
- You can confirm the existence of this directive by opening the page and searching for “noindex” in the response body and response header.
- Blocked by Page Removal Tool
2- You have submitted a request to remove the URL of these pages on GSC.
- Google only attends this request for 90 days, so if you don’t want the page to be indexed, use “noindex” directives, implement HTTP authentication, or remove the page.
3- Banned by robots.txt
- It can still be indexed if Google can find information about that page without loading it. Perhaps a search engine
- You are preventing Googlebot from accessing these pages using a robots.txt file. However Google is indexing the page before adding disallow in robots.txt
Actions to be taken:
- If you don’t want the page to be indexed, use the “noindex” command and remove the robots.txt block.
4- Prohibited due to an unauthorized request (401)
Access to Google using permission request (401 response) is prohibited.
Actions to be taken:
- If you want to allow GoogleBot to visit the page, remove the license requirements.
5- Crawl abnormal
The page was not indexed due to the 4xx or 5xx error response code.
Actions to be taken:
- Use the URL Check tool to get more information about issues.
6- Crawled – Not currently indexed
This page was crawled by GoogleBot but not indexed. It may or may not be indexed in the future. There is no need to submit this URL for crawling.
Actions to be taken:
- If you want the page to be indexed in search results, be sure to provide valuable information.
7- Discovered – Currently Not Indexed
8- Alternate page with the appropriate canonical tag
This page points to a canonical page, so Google understands that you don’t want it indexed.
Actions to be taken:
- If you want this page to be indexed, you will need to change the rel=canonical attributes to give Google the required instructions.
9- Duplicate copy without the main page chosen by the user
The page has exact copies, but none of them are marked as master pages. Google considers this not to be the statute.
Actions to be taken:
- Use canonical tags to indicate to Google which pages are canonical (which should be indexed) and which are duplicate pages. You can use the URL Inspection tool to see which pages have been marked as canonical by Google.
10. Google chose a different canonical address from the user:
You’ve marked this page as a canonical page, but Google, instead, has indexed another page that it thinks works better as a canonical page.
Actions to be taken:
- You can follow Google’s selection. In this case, mark the indexed page as canonical and this page as a duplicate of the canonical URL.
- If not, find out why Google prefers another page over your chosen one, and do
necessary changes. Use the URL Inspection tool to discover the “canonical page” specified by Google.
11- Not Found (404)
The page displays a 404 error status code when Google makes a request. GoogleBot did not find the page through the sitemap, but possibly through another website that links to the URL. It is also possible that this URL existed in the past and was removed.
Actions to be taken:
- If the response is a 404 intended, you can leave it as is. It will not harm your SEO performance. However, if the page has moved, do a 301 redirect.
12- The page was removed due to a legal complaint
This page has been removed from the index due to a legal complaint.
Actions to be taken:
- Check the legal rules you may have violated and take action to correct them.
13- The page that contains the redirect
This URL is a redirect and therefore not indexed.
Actions to be taken:
- If the URL is not supposed to redirect, remove the redirect implementation.
14- soft 404
The page returns what Google thinks is a soft 404 response. The page is not indexed because even though it provides a 200 status code, Googles thinks it should return a 404.
Actions to be taken:
- See if you should set a 404 for the page, as Google suggests.
- Add valuable content to the page to let Google know it’s not a Soft 404.
15- Duplicate URL, submitted and not specified as canonical URL
You have submitted the URL to GSC for indexing purposes. However, it is not indexed because the page has duplicates without canonical tags, and Google considers a better candidate for the canonical page.
Actions to be taken:
- Decide if you want to continue with Google’s selection of the canonical page. In this case, set the rel = canonical attributes to point to the page specified by Google.
- You can use the URL Inspection tool to see which page Google has chosen as the canonical page.
- If you want this URL as the canonical, analyze why Google prefers the other page. Offer more high-value content on the page of your choice.
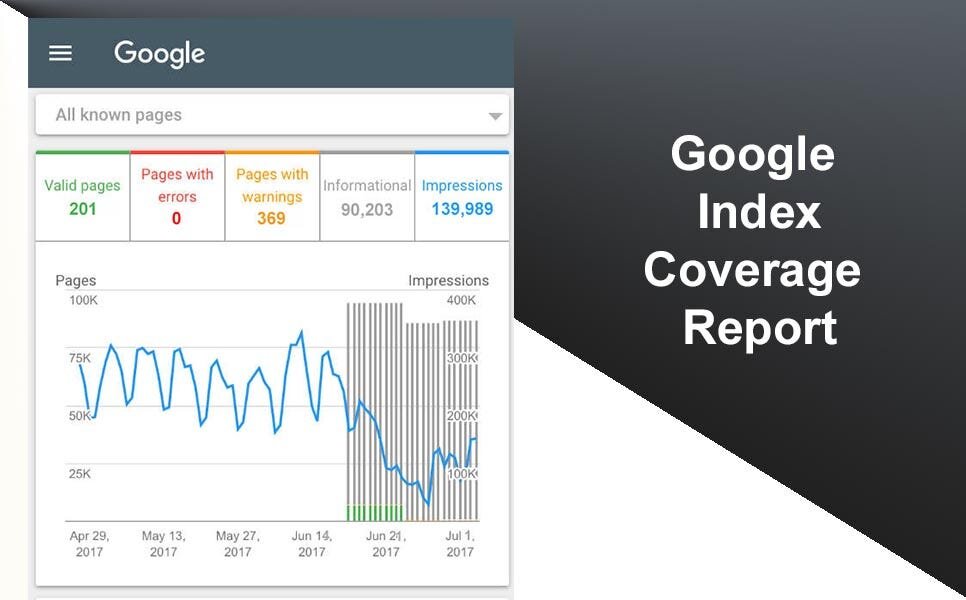
Report the most common index coverage issue
More than valid pages were excluded
Sometimes you can have more excluded pages than valid pages. This circumstance is usually served on large sites that have experienced a significant URL change. Maybe it’s an old site with a long history, or the web code has been modified.
If you have a large difference between the number of pages of the two cases (excluded and valid), then you have a serious problem. Start by reviewing the excluded pages, as we explained above in the Index Coverage Report
error mutations
When the number of errors increases dramatically, you need to check the error and fix it as soon as possible. Google has detected some issues that seriously damage your website’s performance. If you don’t fix the problem today, you’ll have big problems tomorrow.
server errors
Make sure these errors are not 503 (Service Unavailable). This status code means that the server cannot process the request due to temporary overload or maintenance, which can negatively affect index cover performance. At first, the error should go away on its own, but if it keeps happening, you should investigate the issue and fix it. It also appears that Google has detected some areas of your website generating 404 – Pages Not Found, especially if the number increases significantly.
Missing pages or sites
If you can’t see a page or site in the report, it could be due to several reasons.
1- Google hasn’t discovered it yet. When the page or site is new, it may take some time before Google finds it. Submit a sitemap or page crawl request to speed up the indexing process. Also, make sure that the page is not an orphan and is linked from the site.
2- Google cannot access your page based on the login request. Remove the authorization requirement to allow GoogleBot to crawl the page.
3-The page has a noindex tag or has been omitted from the index for some reason. Remove the noindex tag and make sure you provide valuable content on the page.
Errors and exceptions
This problem occurs when there is a discrepancy. If you submit a page via a sitemap, you must ensure that it is indexable, and that it is linked to the site. Your site should mostly consist of valuable pages worth linking to.
Do you need a consultation about this topic?
Contact on WhatsApp